As a fish out of water: Implementing event sourcing for land based fish farming Link to heading
I’m a developer at a company that specializes in designing and constructing land-based fish farming facilities. Complementary to this, we develop the software systems that enable our customers to operate these complex environments with optimal efficiency.
Why Land-Based Fish Farming Needs Specialized Software
Land-based aquaculture operates under distinct constraints compared to traditional sea-based farming, particularly concerning physical space. This necessitates highly precise planning, logistics, and operational monitoring to ensure viability. Observing the existing software landscape, we identified a need for tools specifically tailored to the challenges of land-based systems, especially regarding robust data management and maintaining historical accuracy over time.
Real-World Data Entry Challenges
One of our applications assists farmers with recording essential daily data – fish mortality, sample weights, water quality parameters, and more. The operational environment of a fish farm presents inherent difficulties for data entry. Users may be dealing with equipment or animals while interacting with mobile devices, increasing the likelihood of errors. Furthermore, immediate data entry isn’t always feasible; registrations might be postponed due to more urgent tasks and entered days later, potentially out of chronological sequence with other records. The software needed flexibility to accommodate these realities without burdening the user. Each type of registration had specific frontend implementation to accomodate some of the practical challenges, and features like offline draft saving helped mitigate interruptions.
Our initial focus was on reliable data capture. However, a critical operational requirement soon became apparent: how should the system handle registrations that are later found to be incorrect or need to be logically retracted? Our early system design, centered on logging incoming data, lacked a mechanism for corrections or retractions that didn’t compromise the integrity of the historical record. Simply overwriting existing data would erase the context of the original entry, while deletion would remove the record entirely, hindering accurate auditing and reporting. If you need to account for wrongful registrations, you should also account for wrongful deletion, to a degree. We needed a method to reflect corrections while preserving the complete sequence of events.
Why CRUD Falls Short for Auditable Systems
The conventional database approach using CRUD operations proved inadequate for our requirements, particularly where historical accuracy and auditability are critical.
- Loss of Historical Context: Standard
UPDATEoperations overwrite previous data states, andDELETEoperations remove records permanently. This eliminates the ability to trace the history of data changes or understand the state progression over time. - Difficulty Reconstructing Past States: Without a preserved sequence of changes, accurately calculating the system’s state at a specific point in the past becomes complex and error-prone, especially when dealing with back-dated entries and corrections.
- Inadequate Audit Trails: Basic CRUD operations do not inherently capture the metadata associated with a change, such as the reason for correction or the original value, which are often necessary for compliance and process analysis.
This table summarizes the limitations we faced:
| Challenge | CRUD Approach Limitation | Event Sourcing Solution |
|---|---|---|
| Data Correction | Overwrites history | Immutable correction events |
| Delayed Registration | Hard to insert chronologically | Events placed by actual occurrence time |
| Audit & Compliance | No reliable, built-in history | Full, append-only event log |
| Accurate Reporting | Risk of inaccurate historical data | Replay events for any date |
| Logical Deletions | Permanent removal | Specific “retraction” events |
How Event Sourcing Solves These Problems
These limitations guided us toward exploring Event Sourcing. This pattern shifts the focus from storing the current state to storing a complete, chronological sequence of immutable events that describe every state change.
- Events as Immutable Facts: Each registration, modification, or logical deletion is recorded as a distinct, unchangeable event record (e.g.,
FishCountRegistered,RegistrationCorrected,MortalityEntryRetracted). Corrections involve appending new events that reference the original. - The Append-Only Event Store: Events are added chronologically to an event store. Existing events are never modified or deleted, providing an inherent and reliable audit trail.
- State Reconstruction: The state of any entity at any point in time is determined by replaying the relevant sequence of events from the store. To calculate the state for a specific past date, events are replayed up to that point.
- Snapshots for Optimization: Replaying a very long event history can become computationally expensive. A common optimization pattern is snapshotting, where the derived state of an entity is periodically saved. To reconstruct the state, the system loads the most recent snapshot and replays only the events that occurred after that snapshot, significantly improving performance.
- Projections for Queries: To efficiently serve read requests, background processes (event handlers) listen to the event stream and update separate read-optimized data models, often called projections or materialized views.
Event sourcing appeared well-suited to our requirements, directly addressing the need for auditability, corrections, and accurate historical state calculation. We recognized potential trade-offs, including increased storage consumption compared to state-based storage, the need for careful management of event schema evolution (“versioning”), and the development effort required for the replay and projection logic.
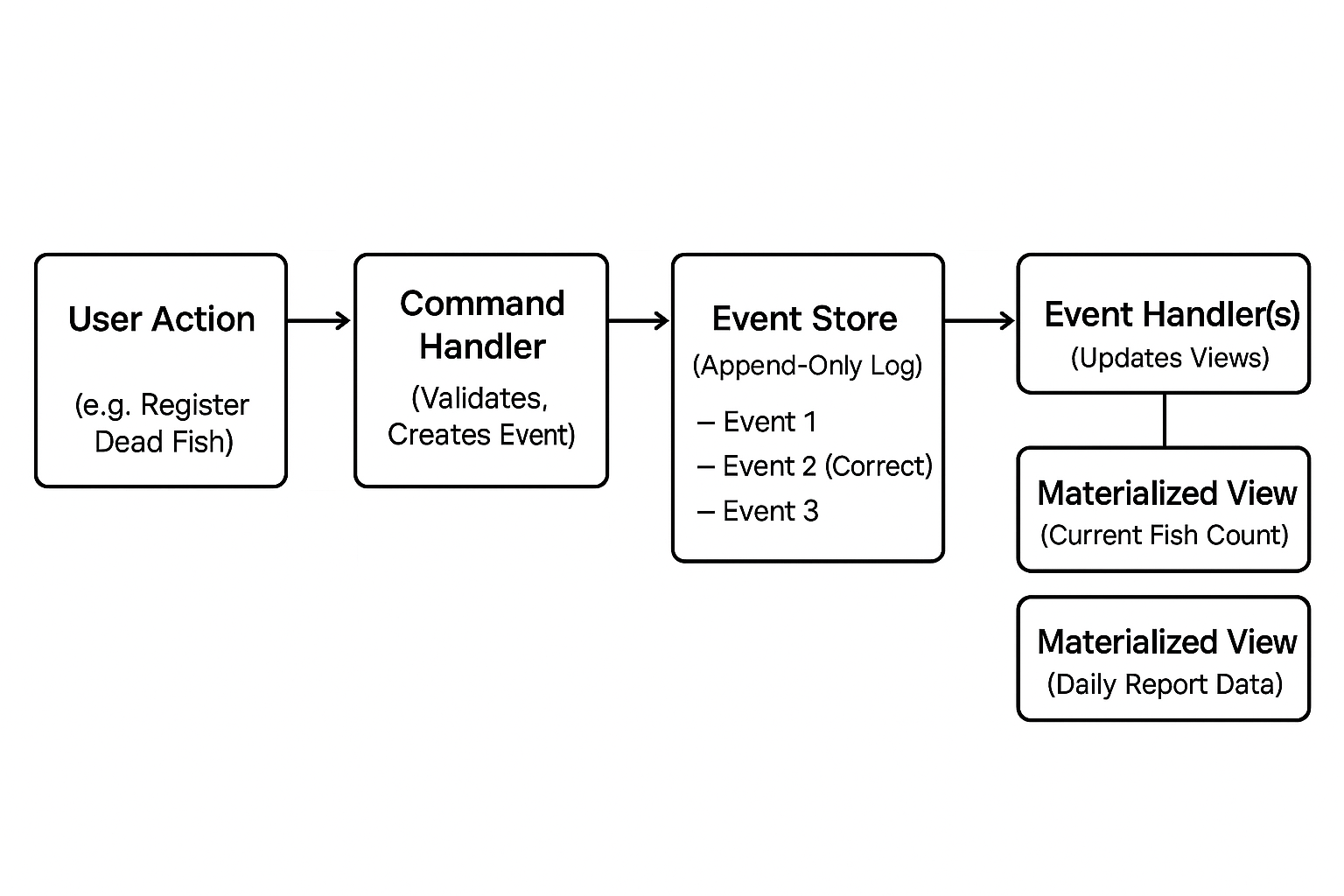
Implementation in Practice: Our Approach
Leveraging our existing microservices architecture allowed us to introduce a dedicated “Event Replay Service” without a major system overhaul.
-
Our Implementation: Relational Event Store: While NoSQL databases are common for event stores due to schema flexibility, we chose to utilize our existing relational (SQL) database infrastructure. We were already showing the user a complete log of registrations, so we had a table in our db with a simple generic event model that placed all registration along one single time-column, which is perhaps the most important part of the event log. This event log was linked to from specific tables holding the detailed payloads for different event types. We kept this approach to avoid a complete rewrite of multiple services, though it requires disciplined schema management for event structures. To support new types of registrations we had also begun work on a more generic event model that could more dynamically define what metrics to hold, which I believe will come in handy so we avoid constantly changing the core event model.
-
Event Replay Service & Snapshot Utilization: This service consumes new events, ensures correct chronological processing, executes the associated business logic (including handling correction and retraction events), and updates the base tables that feed our read models. In order to avoid replaying events from zero each time, we integrated this with our pre-existing daily state snapshots, originally generated for reporting. When recalculating state due to a new event, the Replay Service loads the relevant snapshot from the end of the previous day and replays only the events that occurred since that snapshot. This reuse significantly optimizes recalculation time, making the process efficient even with growing histories. The service subsequently updates relevant future snapshots.
-
Improved Testability: A lot of the domain logic surrounding the registrations were building up in our API that was receiving them, and it was being implemented a little bit ad-hoc on a case by case basis. It wasn’t particularly testable, but it was obvious that a lot of code could be generalized around the core event model, and from there it should be possible to abstract away the domain logic in a generalized way. So the new event service was a pretty big downpayment on technical debt that was building up, we now have unit tests both on the common state-update logic, and on the specific domain logic that now presents a common interface.
-
Event Queue (Azure Storage Queues Initially): We employ Azure Storage Queues for asynchronous notification between event persistence and the Replay Service. We had a storage account from before so it was a quick way to get a queue up and running, but I think we could benefit from something with either a better push-interface to simplify the queue-client code compared to frequent polling, or something that can handle more volume. Although that would primarily be to support a completely separate sensor data-pipeline.
-
Projections via SQL Views: We implemented read models using standard SQL Views over the base registration tables. This leverages our existing database capabilities effectively for current query requirements and simplifies the infrastructure compared to managing separate read stores.
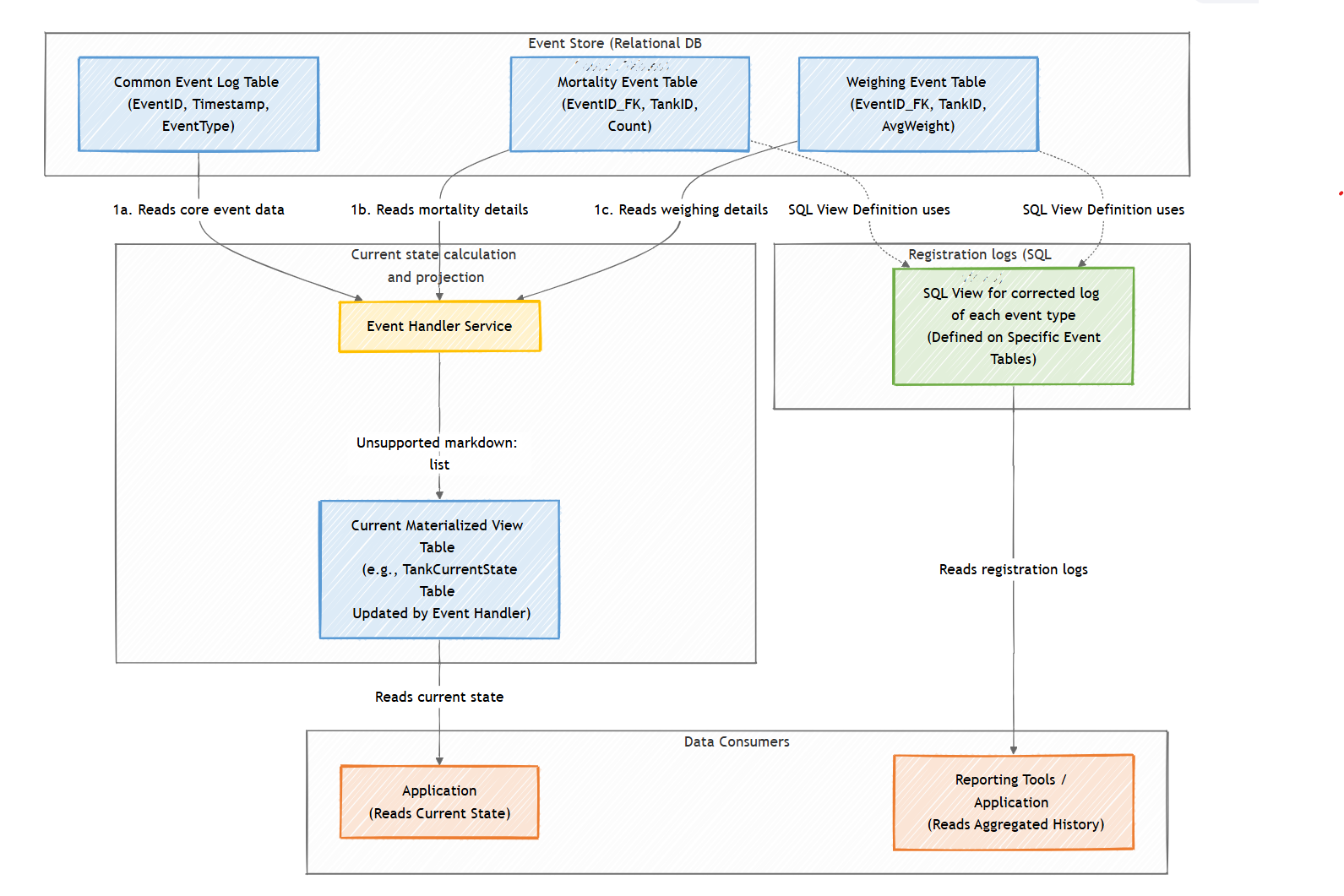
-
Relation to CQRS: While not an explicit goal, adopting event sourcing resulted in a degree of Command Query Responsibility Segregation (CQRS). The “command” side handles incoming actions and persists events. The “query” side involves the Event Replay Service updating projections (base tables/views) optimized for reading. This logical separation exists without the complexity of fully separate read/write models or databases. This meets our current needs, although a more formal CQRS implementation might be considered if future query complexity increases significantly.
Lessons Learned and Next Steps
Transitioning to an event-sourcing-based model has substantially improved our data management capabilities.
- Key Benefits Realized:
- Complete Auditability: Provides a full, immutable history.
- Robust Data Correction: Handles errors and retractions gracefully.
- Accurate Historical State: Enables precise point-in-time reporting.
- Centralized Business Logic: Reduced API complexity and technical debt.
- Enhanced Testability: Increased confidence through focused unit testing.
Our implementation, using a relational store and existing daily snapshots, represents a pragmatic adaptation that effectively solved our specific challenges. However, development is an ongoing process.
- Next Steps and Future Considerations:
- Event Queue Evolution: We plan to evaluate migrating from Azure Storage Queues. Azure Event Hub is a candidate for handling potentially higher event volumes.Azure Service Bus offers richer features like advanced dead-lettering and potentially easier duplicate detection, which could simplify consumer logic. The choice will depend on evolving throughput and feature requirements.
- Snapshot Strategy Refinement: While daily snapshots work well now, we may need to refine this. This could involve adjusting the frequency or storing more data in each snapshot, because now its really minimal as required by reporting.
- Projection Optimization: If read performance degrades due to complex queries or high load, we may need to optimize projections further, potentially introducing dedicated, denormalized read models (moving closer to a formal CQRS architecture).
- Error handling: Handling errors in the pipeline is still not where it needs to be for us to be completely confident. What happens if the queue trigger payload cannot be read/serialized, do we delete it from the queue? Presumably, it was put there by a real event happening, do we need to alert someone to manually resolve the issue, so we don’t miss an update?
This architectural shift has provided a solid foundation for managing complex operational data in land-based aquaculture, enabling both accurate historical perspective and robust handling of real-world data challenges.